CCA Foundations Exam Complete Guide 2026: The Fastest Path to Claude Certified Architect
swiftwand swiftwand.ai

Domain 1: Agentic Architecture & Orchestration carries the highest weight at 27% of the CCA Foundations exam. Furthermore, this domain’s 7 task statements appear across 4 of the 6 exam scenarios, making it the most versatile knowledge area. Mastering D1 is the single most impactful investment for exam success.
Moreover, this article covers the first 3 task statements (T1.1-T1.3): Agent Loop Design, Multi-Agent Orchestration, and Sub-Agent Spawning. These form the architectural foundation that all other domain knowledge builds upon.

At 27%, D1 alone accounts for approximately 16 of the 60 exam questions. Additionally, a strong D1 performance provides a buffer that can compensate for weaker areas in D2 (18%) or D5 (15%). Consequently, your study plan should allocate proportionally more time to D1.
An agent loop follows a predictable lifecycle: receive input, call the model, check stop_reason, execute tools if needed, and repeat. Furthermore, the stop_reason field is the definitive signal for loop control — it tells you whether the model wants to use a tool (tool_use) or has finished (end_turn).
When stop_reason is “tool_use,” the agent must execute the requested tool and feed the result back into the conversation. Additionally, when stop_reason is “end_turn,” the agent should terminate the loop and return the final response. Moreover, when stop_reason is “max_tokens,” the context window is full and requires truncation or summarization strategies.
The canonical agent loop pattern in Python involves a while loop that continues as long as stop_reason equals “tool_use.” Furthermore, inside the loop, each tool call is extracted, executed, and its result appended to the messages array as a tool_result content block.
The most common anti-pattern is “parsing natural language signals to determine loop termination.” Specifically, checking if the model’s text contains phrases like “I’m done” or “task complete” is unreliable. Additionally, the correct approach always uses stop_reason — it’s the only deterministic signal available.
Moreover, another anti-pattern is “hardcoding maximum loop iterations without graceful degradation.” While iteration limits are reasonable safety measures, they should trigger a structured error response rather than silent failure.
Expect questions like: “Given an agent that occasionally terminates prematurely, which implementation change would most reliably fix the issue?” Furthermore, the correct answer invariably involves stop_reason-based control rather than text parsing or timeout-based approaches.
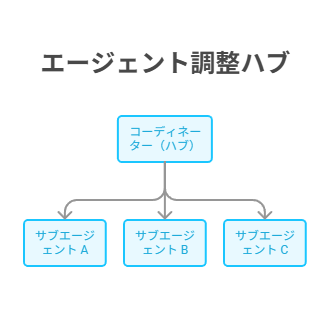
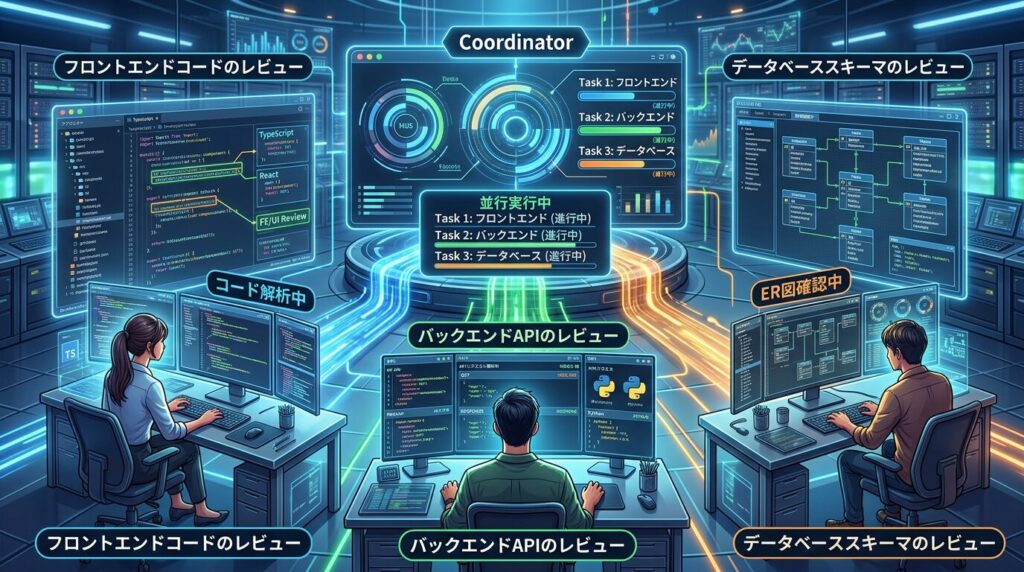
The Hub-and-Spoke pattern places a coordinator agent at the center, delegating specialized tasks to subagents. Additionally, the coordinator is responsible for task decomposition, subagent selection, result aggregation, and error handling.
The coordinator must handle: (1) interpreting the user request and decomposing it into subtasks, (2) selecting appropriate subagents for each subtask, (3) managing execution order (parallel vs sequential), (4) aggregating results from subagents, and (5) handling errors and fallback strategies. Furthermore, understanding these 5 responsibilities is critical for exam scenarios.
Subagents operate in isolated contexts, meaning they do not share conversation history with each other. Moreover, this isolation is intentional — it prevents context pollution and ensures each subagent focuses on its specific task. The coordinator must explicitly pass relevant context to each subagent.
Key anti-patterns include: sharing full conversation history with all subagents (context pollution), creating overly granular subagents (coordination overhead exceeds benefit), and failing to implement error propagation from subagents to coordinator. Additionally, the exam frequently tests whether candidates understand the trade-offs of agent granularity.

The Task tool is the primary mechanism for spawning subagents in Claude’s Agent SDK. Furthermore, it creates a new agent instance with its own conversation context, tool set, and system prompt. The spawning agent receives a structured result when the subagent completes.
Every AgentDefinition requires: (1) a system prompt defining the subagent’s role and constraints, (2) a tool set scoping what actions the subagent can take, and (3) output format specification defining the expected result structure. Additionally, understanding how these elements interact is essential for exam questions about subagent design.
The fork_session mechanism creates a copy of the current conversation state for exploratory branching. Moreover, this is useful when you need to try multiple approaches in parallel without contaminating the main conversation thread.
Parallel execution is appropriate when subtasks are independent and don’t depend on each other’s results. Furthermore, sequential execution is necessary when later tasks depend on earlier results. The exam tests your ability to identify these dependencies and choose the correct execution strategy.
_├──-Fork-A-パフォーマンス最適化の検討_├──-Fork-B-セキュリティ強化の検討_└──-Fork-C-182121-1024x572.jpg)
Design a multi-agent code review system where a coordinator receives a pull request, spawns specialized subagents for security analysis, performance review, and style checking, then aggregates results into a unified review report. Furthermore, apply the patterns from T1.1 (loop design), T1.2 (orchestration), and T1.3 (spawning) to create your design.
Moreover, the coordinator should use the hub-and-spoke pattern with parallel subagent execution (since the three review types are independent). Each subagent operates in an isolated context with scoped tool access. Additionally, the agent loop uses stop_reason-based control for reliable termination.
When answering multi-agent questions, look for answers that: use stop_reason for loop control, maintain isolated subagent contexts, implement proper error propagation, and use programmatic enforcement for critical policies. Furthermore, answers that rely on prompt-based guidance alone for safety-critical decisions are typically incorrect.
If stuck between two answers, prefer the one that: (1) uses deterministic mechanisms over probabilistic ones, (2) maintains context isolation, and (3) provides structured error handling. Additionally, remember that the exam values “design judgment” — understanding why an approach is correct matters more than memorizing code patterns.
Apply T1.1-T1.3 to design a customer support system with intent routing, specialized handlers for billing/technical/general queries, and escalation workflows. Moreover, consider how the coordinator manages context passing, how subagents maintain isolation, and how the agent loop handles tool failures gracefully.
Furthermore, this exercise prepares you for Scenario S1 (Customer Service Automation), which is one of the most frequently tested scenarios in the CCA exam.
For more information, visit Anthropic Documentation.