"Looking Good" Is Calculable: How AI Product Photography Transforms 3D Print Sales
swiftwand swiftwand.ai

The final installment in the CCA Foundations exam prep series. This article thoroughly explains all 6 tasks of Domain 5 “Context Management & Reliability” (15% weight), plus provides a comprehensive series summary with cross-domain review of all 5 domains, anti-pattern catalog, 5 mock questions, and exam-day time allocation strategy. This is the definitive guide for CCA exam context management, reliability, and summary.
In our previous D4 Prompt Engineering article, we covered structured output and validation. D5 addresses whether that output “remains accurate over time” and “how to recover from failures.” This domain tests the knowledge needed for agents to be not just “usable” but “trustworthy.”
As described in the series’ first Complete Guide, CCA Foundations is a scenario-based exam with 60 questions in 120 minutes, requiring 720/1000 to pass. D5 is worth 15% (approximately 9 questions), but reliability concepts frequently appear in D1 (agent design) and D2 (tool design) questions, making the effective impact significantly larger.

Specifically, the first theme in CCA exam context management, reliability, and summary is context degradation in long-running conversations.
In particular, during long agent sessions, context window constraints force repeated summarization. The first information lost in this process is “specific facts.”
Order number A-20250315-4472, refund amount $127.50 → After summarization, degrades to “regarding the recent order refund”
Amounts, dates, and identifiers are the first information categories lost in the summarization process.
Additionally, LLMs exhibit a “U-shaped attention pattern” biased toward the beginning and end of inputs. Information in the middle of long inputs is more likely to be overlooked. Placing important finding summaries at the beginning of the input counters this positional effect.
For example, the core countermeasure is the “Case Facts block.” Preserve transactional facts (amounts, dates, IDs) in a structured block that remains anchored at the top of the context, immune to summarization.
# Case Facts (DO NOT SUMMARIZE)
- Order: A-20250315-4472
- Customer: C-98231
- Issue: Damaged item
- Refund amount: $127.50
- Photos: Received and verifiedKey Point: In CCA exams, when “facts are lost after long sessions” is described, the correct answer is always Case Facts pattern (structured fact preservation), not “increase context window” or “summarize more frequently.”
Sentiment analysis scores and keyword matching are unreliable for escalation decisions. A customer saying “this is terrible” might be expressing frustration about a product, not requesting human assistance. Only explicit requests and safety triggers are reliable.
escalation_handoff = {
"reason": "customer_requested_human",
"conversation_summary": "Refund request for damaged item on order A-20250315-4472",
"case_facts": {
"order_number": "A-20250315-4472",
"customer_id": "C-98231",
"refund_amount": "$127.50",
"issue_type": "damaged_item"
},
"actions_taken": [
"Verified order status (delivered)",
"Received damage photos"
],
"pending_actions": ["Refund processing approval"],
"escalation_priority": "medium"
}In conclusion, handoffs should include conversation summary, Case Facts, actions taken, and pending actions in a structured format. The human operator shouldn’t need to understand the situation “from scratch.”
Key Point
Furthermore, in multi-agent architectures, how sub-agent failures are reported determines reliability. Error reports should include 4 elements: failure type, attempted queries, partial results, and alternative approach suggestions.
error_context = {
"status": "partial_failure",
"failure_type": "api_timeout",
"attempted_queries": ["search: auth vulnerabilities", "search: JWT bypass"],
"partial_results": [
{"source": "internal_db", "findings": 3, "status": "complete"},
{"source": "external_api", "findings": 0, "status": "timeout"}
],
"alternative_approaches": [
"Retry external API with increased timeout",
"Use cached results from last scan"
]
}This is the most important distinction in T5.3. An empty result from a search that successfully executed means “no matches found” — a valid finding. An empty result from a timed-out API means “we don’t know” — an access failure requiring different handling.
| Scenario | Classification | Correct Action |
|---|---|---|
| Search returned 0 results | Valid empty result | Report “no issues found” with confidence |
| API timed out, no data returned | Access failure | Report failure, suggest retry or alternatives |

When context windows fill up, quality degrades. Watch for: repeated questions about previously established facts, contradicting earlier statements, forgetting task constraints, and hallucinating details.
For long-running agent tasks, maintain a progress manifest that enables recovery from crashes:
progress_manifest = {
"task": "security_audit",
"started_at": "2026-03-20T10:00:00Z",
"completed": [
"src/auth/jwt.py",
"src/auth/middleware.py",
"src/models/user.py"
],
"key_findings": [
"JWT verification at middleware.py:L45",
"User model missing role field"
],
"pending_tasks": [
"src/auth/permissions.py analysis",
"Test coverage verification"
],
"scratchpad_path": "/tmp/explorer_01_findings.md"
}The coordinator reads this manifest, retrieves the completed list, findings, and resume_from (pending tasks) to resume from the interruption point.
Key Point
In CCA exam context management, reliability, and summary, this topic is particularly important.
Additionally, 97% overall accuracy isn’t reassuring. Poor performance in specific categories may be hidden.
For example, automation decisions should be made after verifying accuracy by document type and field.
Therefore, sampling design is needed to measure error rates in high-confidence extractions and detect new error patterns. Verify accuracy across document type × field combinations.
When a model reports “high confidence” on 100 extractions, ideally 95%+ should be correct. If only 80% are correct, the model is overconfident. Track calibration metrics and adjust thresholds accordingly.

Every factual claim in synthesized output should be traceable to its source. This is especially critical in research, legal, and compliance contexts.
Key Point: The claim-source mapping pattern preserves the link between each assertion and its origin. When sources conflict, present both with attribution rather than silently choosing one.
When Source A says “market size is $5B” and Source B says “$7B,” the correct approach is to present both figures with their sources, not to average them or pick one. Let the human reader assess source reliability.
When a coordinator decomposes research into sub-tasks, each sub-agent may find different facts. The coordinator must preserve all source attributions when synthesizing, not discard them.
| Situation | Correct Approach | Incorrect Approach |
|---|---|---|
| Facts lost in long sessions | Case Facts pattern (structured preservation) | More frequent summarization |
| Customer says “let me talk to a person” | Immediate escalation with structured handoff | Sentiment analysis to assess urgency |
| Sub-agent timeout | Structured error context with alternatives | Return empty results silently |
| Numerical contradictions between sources | Present both with attribution | Choose one or average them |
| Accuracy metrics | Verify at fine granularity | Trust overall averages |
Additionally, from here we provide the series comprehensive summary, cross-referencing important concepts across all 5 domains and 30 tasks.
| Domain | Weight | Tasks | Core Theme | Key Keywords |
|---|---|---|---|---|
| D1: Agentic Architecture | 27% | 7 | Agent loops, multi-agent, task decomposition | stop_reason, allowedTools, fork_session, PostToolUse |
| D2: Tool Design & MCP | 18% | 5 | Tool descriptions, MCP, structured errors | isError, errorCategory, tool_choice, .mcp.json |
| D3: Claude Code Config | 20% | 6 | CLAUDE.md hierarchy, commands, CI/CD | .claude/rules/, context: fork, -p flag |
| D4: Prompt Engineering | 20% | 6 | Few-shot, tool_use, Batch API | tool_choice: “any”, JSON Schema, Message Batches API |
| D5: Context & Reliability | 15% | 6 | Context preservation, escalation, error propagation | Case Facts, claim-source mapping, stratified sampling |
Key Point
In other words, domains are not tested in isolation. Scenario questions simultaneously require knowledge from multiple domains.
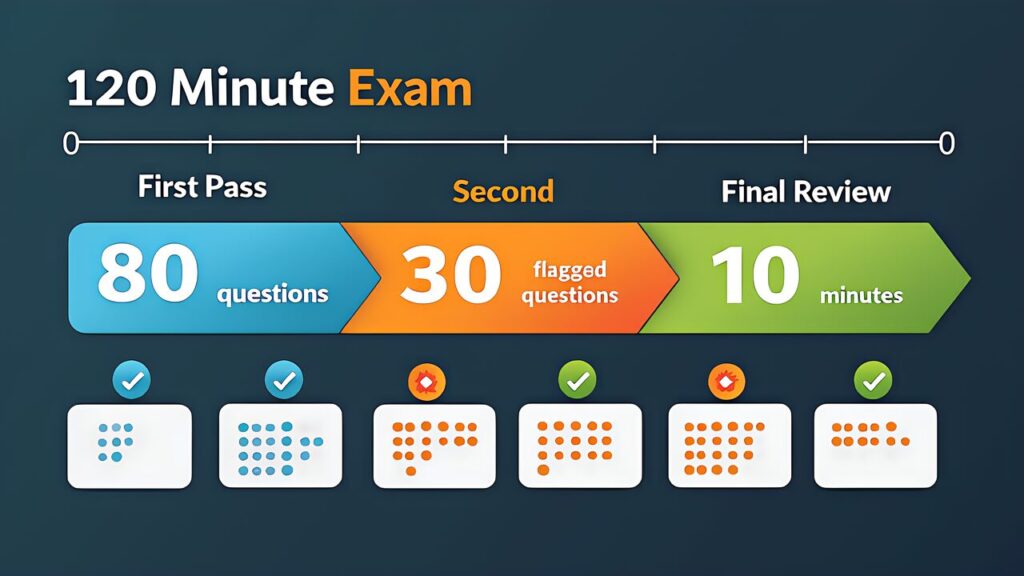
Specifically, 120 minutes ÷ 60 questions = 2 minutes/question. However, not all questions have equal difficulty.
| Phase | Time | Action |
|---|---|---|
| First pass (0-80 min) | 80 min | Go through all 60 questions. Answer confident ones, flag uncertain ones |
| Second pass (80-110 min) | 30 min | Review flagged questions. Use elimination to narrow down |
| Final review (110-120 min) | 10 min | Overall review. Ensure no unanswered questions |
Additionally, in CCA’s 4-choice questions, three distractors are “partially correct but suboptimal from a specific perspective.” Eliminate using these patterns:
For example, D1 (27%) + D3 (20%) = 47%. These two domains alone account for nearly half the exam. Candidates strong in D1 and D3 can pass even if they drop a few D5 questions. Conversely, weaknesses in D1 should be addressed as the highest priority.
Q1 (D1 + D5 Mixed): A customer support agent’s process_refund tool is called without completing get_customer 12% of the time. Most effective countermeasure?
A) Add “always call get_customer first” to system prompt
B) Show correct order with few-shot examples
C) Block with programmatic prerequisite gate requiring get_customer completion
D) Add ordering notes to process_refund’s tool description
Correct: C — When deterministic compliance is required, prompt instructions (A, B, D) leave non-zero failure rates. Code-level enforcement is the only guarantee.
Q2 (D2 + D5 Mixed): A web search sub-agent times out. What is the most appropriate way to report to the coordinator?
A) Return an empty results list
B) Return an error message “search service unavailable”
C) Abort the entire workflow
D) Return structured error context with failure type, attempted queries, and alternative approaches
Correct: D — Structured error context enables the coordinator to make informed decisions. Empty results (A) conflate access failure with valid empty results.
Q3 (D3 + D4 Mixed): Test files are scattered across the project and you want consistent naming conventions. Most efficient approach?
A) Add conventions to project root CLAUDE.md
B) Create a glob-pattern rule in .claude/rules/
C) Place CLAUDE.md in each test directory
D) Add few-shot examples in system prompt
Correct: B — Glob patterns efficiently apply cross-cutting rules with good token efficiency.
Q4 (D4 + D5 Mixed): Invoice extraction shows 97% overall accuracy but you suspect hidden issues. What should you do?
A) Deploy to production with 97% confidence
B) Perform stratified analysis by document type and field
C) Add more few-shot examples
D) Lower the confidence threshold
Correct: B — Overall metrics can mask category-specific problems. Granular verification is essential.
Q5 (D1 + D2 + D3 Mixed): A CI pipeline using Claude Code for PR review hangs. What is the most likely cause?
A) MCP server connection failed
B) Missing -p flag for non-interactive mode
C) CLAUDE.md has syntax errors
D) tool_choice is set incorrectly
Correct: B — The -p flag is essential for CI environments. Without it, Claude Code waits for interactive input.
Key Point: This article completes the CCA exam prep series covering all 5 domains. For practical preparation, combine hands-on learning through the Anthropic Academy official course with practice on mock exam sites. Refer to our Complete Guide (Day 1) for the recommended “three-pillar” study strategy. Good luck on the exam!
For more information, visit Anthropic Official.