Input Shaping 完全攻略 — 加速度センサーで「振動」を補正する物理学
ゲンキ swiftwand.ai

CCA Foundations試験対策シリーズの最終回。本記事ではDomain 5「Context Management & Reliability」(配点15%)の全6タスクを徹底解説し、さらにシリーズ全体の総まとめとして5ドメインの横断整理、アンチパターン一覧、模擬問題5問、そして本番での時間配分戦略を提供する。つまり、CCA試験 コンテキスト管理 信頼性 まとめの決定版だ。
前回のD4プロンプトエンジニアリング編で構造化出力とバリデーションを学んだ。具体的には、今回のD5は、その出力が「長期にわたって正確に維持されるか」「障害時にどう回復するか」を扱うドメインだ。特に、エージェントが「使える」だけでなく「信頼できる」ものになるための知識が問われる。
さらに、シリーズ第1回の完全ガイドで述べたとおり、CCA Foundationsは60問・120分・合格点720/1000のシナリオベース試験だ。加えて、D5は配点15%で約9問に相当するが、信頼性の概念はD1(エージェント設計)やD2(ツール設計)の問題にも頻出するため、実質的な影響範囲はそれ以上に大きい。


特に、CCA試験 コンテキスト管理 信頼性 まとめの第一テーマは、長期対話におけるコンテキスト劣化だ。
具体的には、長時間のエージェントセッションでは、コンテキストウィンドウの制約により要約が繰り返される。したがって、この過程で最初に失われるのは「具体的事実」だ。
#A-20250315-4472、返金額 $127.50 → 要約後「先日の注文の返金について」に劣化加えて、LLMは入力の先頭と末尾に注意が偏る「U字型の注意パターン」を持つ。同様に、長い入力の中間部分にある情報は見落とされやすい。結論として、重要な発見事項のサマリーを入力の先頭に配置することで、この位置効果に対抗できる。
例えば、対策の核心は「Case Facts ブロック」だ。例えば、取引事実(金額・日付・注文番号)を永続的な構造化ブロックに抽出し、要約対象から除外する。
# Case Facts ブロック -- 要約対象から除外される永続情報
case_facts = {
"customer_id": "C-98231",
"order_number": "#A-20250315-4472",
"refund_amount": "$127.50",
# --- 基本情報 ---
"order_date": "2025-03-15",
"issue_type": "damaged_item",
"interaction_start": "2025-03-18T14:22:00Z"
}
したがって、ツール呼び出し結果が蓄積されてコンテキストを圧迫する問題には、出力トリミングで対処する。同様に、冗長なJSONレスポンスから関連フィールドのみを抽出し、サブエージェントの出力にはメタデータ(日付・ソース・手法)を構造化形式で含める設計にする。
一方、エスカレーション判断はCCA試験で最も頻出するパターンの一つだ。
同様に、試験で最も問われるのは条件1だ。結論として、「顧客が人間を要求したが、エージェントは原因を特定しかけている」というシナリオでは、即座にエスカレーションが正解。したがって、問題解決を続行するのは誤りだ。
また、以下はエスカレーション判断の根拠として使うべきでない。
しかし、複数の顧客レコードが一致した場合も、「最も可能性の高い」レコードを推測で選択してはならない。具体的には、追加の識別情報(メールアドレス、電話番号の下4桁など)を顧客に確認する。
escalation_handoff = {
"reason": "customer_requested_human",
"conversation_summary": "注文 #A-20250315-4472 の破損品に関する返金リクエスト",
"case_facts": {
# --- 基本情報 ---
"order_number": "#A-20250315-4472",
"customer_id": "C-98231",
"refund_amount": "$127.50",
# --- 詳細データ ---
"issue_type": "damaged_item"
},
"actions_taken": [
"注文ステータスを確認(配送済み)",
# --- 関連情報 ---
"破損品の写真を受領済み"
],
"pending_actions": ["返金処理の承認"],
"escalation_priority": "medium"
}
結論として、引き継ぎ時には会話サマリー、Case Facts、実行済みアクション、未完了アクションを構造化して含める。一方、人間のオペレータが「ゼロから」状況を把握する必要がないようにする。
さらに、マルチエージェントアーキテクチャにおいて、サブエージェントの障害をどう報告するかが信頼性を決定づける。まず、エラー発生時に返すべき情報は4要素だ。
error_context = {
"status": "partial_failure","failure_type": "access_timeout",
"attempted_queries": ["AI creative industry 2025", "generative AI art market"],
"partial_results": [{"source": "cached_data", "coverage": "60%"}],
# --- 基本情報 ---
"alternative_approaches": ["try academic_search tool", "use cached results"],
"is_retryable": True,
"retry_after_seconds": 30
}| 状況 | 意味 | 正しい対応 |
|---|---|---|
| アクセス障害(タイムアウト等) | データ取得に失敗 | 構造化エラーを返し、リトライ可否を明示 |
| 有効な空結果 | 正当なクエリに対して該当なし | 「結果なし」を正常な応答として返す |
つまり、空の結果を成功として返すと、コーディネータが障害と正常な「該当なし」を区別できなくなる。最終的に、これはサイレントエラー抑制と呼ばれるアンチパターンだ。
| パターン | 問題点 |
|---|---|
| サイレントエラー抑制 | 空の結果を成功として返す → 障害が認識されない |
| 単一障害で全体停止 | 1つのサブエージェント障害でワークフロー全体を終了させる |
| 汎用エラーステータス | 「検索利用不可」などの汎用メッセージは有用なコンテキストを隠す |
3つのサブエージェントのうち1つがタイムアウトした場合、ワークフローを中止すべきでない。残り2つの結果を活用し、障害エージェントはリトライまたは代替手段で補完する。

特に、大規模コードベースを探索するエージェントセッションで、以下の症状が出たら劣化が発生している。
スクラッチパッドファイル: 重要な発見事項をファイルに永続化し、コンテキスト境界をまたいで情報を保持する。
具体的には、サブエージェント委譲: 冗長な探索出力をメインコンテキストから隔離する。さらに、サブエージェントが探索を行い、構造化されたサマリーのみをコーディネータに返す。
特に、/compactによるコンテキスト圧縮: コンテキスト使用量が増大した場合に会話履歴を圧縮する。また、ただし、重要な事実はCase Factsやスクラッチパッドに事前退避しておく必要がある。
具体的には、エージェントがクラッシュした場合の回復パターンとして、各エージェントが状態を既知の場所にエクスポートする設計がある。
つまり、# 各エージェントが状態をマニフェストにエクスポート
agent_state = {
"agent_id": "code_explorer_01",
"last_checkpoint": "2025-03-18T15:30:00Z",
"files_analyzed": [
# --- 基本情報 ---
"src/auth/jwt.py",
"src/auth/middleware.py",
"src/models/user.py"
],
# --- 詳細データ ---
"key_findings": [
"JWT 検証は middleware.py:L45 で実行",
"User モデルに role フィールドが欠如"
],
# --- 関連情報 ---
"pending_tasks": [
"src/auth/permissions.py の分析",
"テストカバレッジの確認"
],
# --- 追加フィールド ---
"scratchpad_path": "/tmp/explorer_01_findings.md"
}
コーディネータはこのマニフェストを読み込み、completedリスト、findings、resume_from(未完了タスク)を取得して中断地点から再開する。
CCA試験 コンテキスト管理 信頼性 まとめにおいて、このトピックは特に重要だ。
加えて、全体精度97%は安心材料にならない。具体的には、特定のカテゴリでの低パフォーマンスが隠されている可能性がある。
例えば、自動化の判断は、文書タイプ別・フィールド別の精度を検証してから行うべきだ。
したがって、高信頼度の抽出結果に対するエラー率を測定し、新しいエラーパターンを検出するためのサンプリング設計が必要だ。特に、文書タイプ×フィールドの組み合わせで精度を検証する。
# 文書タイプ x フィールドの精度マトリクス
accuracy_matrix = {
"printed_invoice": {"total": 0.98, "amount": 0.99, "date": 0.97, "tax": 0.95},
"handwritten_invoice": {"total": 0.72, "amount": 0.75, "date": 0.68, "tax": 0.61},
"receipt": {"total": 0.94, "amount": 0.96, "date": 0.93, "tax": 0.88}
}
一方、フィールドレベルの信頼度スコアは、ラベル付き検証セットに対して較正(キャリブレーション)されていなければならない。つまり、「信頼度95%」と表示されたものが実際に95%正確であるべきだ。
同様に、較正ギャップが存在する場合(例: 信頼度90-95%バケットの実際の正答率が87%)、信頼度スコアを下方修正するか、閾値を引き上げる必要がある。例えば、これは「過信傾向」と呼ばれる一般的な問題だ。

とりわけ、複数ソースからの情報を統合する際、要約ステップで主張とソースの紐付けが失われることがある。しかし、「AI市場は成長している」という主張がどのレポートに基づくか不明になるのだ。
synthesis_output = {
"claims": [
{
"claim": "AI art market grew 35% in 2025",
"sources": [
{"source": "McKinsey Report 2025", "date": "2025-06", "confidence": "high"},
{"source": "Art Basel Survey", "date": "2025-03", "value": "32%"}
],
"conflicts": "Minor (35% vs 32%) - likely different measurement periods"
}
],
"coverage_gaps": ["音楽・映像分野のデータが不足"],
"temporal_range": "2025-03 to 2025-08"
}
異なるソースが異なる数値を報告した場合、一方を恣意的に選択してはならない。したがって、ソース帰属を注釈として付与し、矛盾を明示する。時期の違い(2025年3月のレポート vs 2025年6月のレポート)による数値差は矛盾ではなく時間経過による変化の可能性があるため、出版日・データ収集日を構造化出力に含めることが重要だ。
結論として、「AI×クリエイティブ産業」の調査で視覚芸術のみをカバーした結果が返された場合、問題はサブエージェントの障害ではなく、コーディネータのタスク分解が狭すぎたことにある。加えて、音楽・映像・文学など他の分野を含むよう分解を修正すべきだ。
さらに、CCA試験 コンテキスト管理 信頼性 まとめの総括として、D5の判断基準を整理する。
| 状況 | 正しい判断 |
|---|---|
| 顧客の明示的要求 | 必ず従う(即時エスカレーション) |
| 曖昧な状況 | ユーザーに確認(推測しない) |
| エラー発生 | 構造化コンテキストで報告(隠さない) |
| 数値の矛盾 | 両方を出典付きで提示(片方を選ばない) |
| 精度指標 | 粒度を細かくして検証(全体平均を信用しない) |
また、ここからはシリーズ総まとめだ。同様に、5ドメイン30タスクの重要概念を横断的に整理する。
| ドメイン | 配点 | タスク数 | 核心テーマ | 最重要キーワード |
|---|---|---|---|---|
| 領域1 — Agentic Architecture & Orchestration | 27% | 7 | エージェントループ、マルチエージェント、タスク分解 | stop_reason, allowedTools, fork_session, PostToolUse |
| 領域2 — Tool Design & MCP Integration | 18% | 5 | ツール記述、MCP、構造化エラー | isError, errorCategory, tool_choice, .mcp.json |
| 領域3 — Claude Code Configuration & Workflows | 20% | 6 | CLAUDE.md階層、スラッシュコマンド、CI/CD | .claude/rules/, context: fork, -pフラグ |
| 領域4 — Prompt Engineering & Structured Output | 20% | 6 | few-shot、tool_use、バッチAPI | tool_choice: "any", JSON Schema, Message Batches API |
| 領域5 — Context Management & Reliability | 15% | 6 | コンテキスト保持、エスカレーション、エラー伝播 | Case Facts, claim-source mapping, 層化サンプリング |
つまり、ドメインは独立して出題されるわけではない。結論として、シナリオ問題では複数ドメインの知識が同時に要求される。
例えば、D1 ↔ D5(最も強い結合): マルチエージェントのタスク分解(D1.2)とエラー伝播(D5.3)は表裏一体。とりわけ、コーディネータの設計が信頼性を決定する。
しかし、D1 ↔ D2: エージェントループ(D1.1)のツール呼び出しにはMCPツール設計(D2.1-2.2)の知識が必要。一方、tool_choiceはD2とD4の両方で出題される。
したがって、D2 ↔ D5: 構造化エラーレスポンス(D2.2)とエラー伝播パターン(D5.3)は同じ設計思想。まず、isErrorフラグとretryable判定はD2で定義し、D5で運用する。
加えて、D3 ↔ D4: CLAUDE.md(D3.1)のルール設計はプロンプトエンジニアリング(D4)そのもの。最終的に、CI/CD統合(D3.6)ではバッチAPI(D4.5)の知識が必要。
同様に、D4 ↔ D5: 構造化出力(D4.3)の信頼性検証は人間レビューワークフロー(D5.5)で行う。さらに、信頼度キャリブレーションはD4のバリデーション設計に直結する。
特に、シリーズ全体で登場したアンチパターンを一覧にまとめる。また、試験では「最も適切でない選択肢」として出題されるため、これらを確実に識別できることが重要だ。
| アンチパターン | 正しいアプローチ |
|---|---|
| 自然言語シグナルのパースでループ終了を判定 | stop_reasonの構造化チェック |
| 任意のイテレーション上限を主要な停止メカニズムに | stop_reason: "end_turn"で終了判定 |
| プロンプト指示だけで決定論的コンプライアンスを保証 | プログラマティック前提条件ゲート(フック) |
| サブエージェントにcoordinatorの全コンテキストを自動継承 | 明示的なプロンプトでコンテキスト提供 |
| アンチパターン | 正しいアプローチ |
|---|---|
| 最小限のツール記述(名前だけ) | 目的・入力・出力・使い分けを詳細に記述 |
| 18個のツールを1エージェントに付与 | 役割に必要な4-5個に限定 |
| 一律のエラーレスポンス(”Operation failed”) | errorCategory, isRetryableを含む構造化エラー |
汎用ツール(fetch_url) | 目的別ツール(load_document)に分割 |
| アンチパターン | 正しいアプローチ |
|---|---|
| ユーザースコープにチーム共有コマンドを配置 | プロジェクトスコープ.claude/commands/を使用 |
| 大規模変更を直接実行 | プランモードで事前検討 |
| 同一セッションで生成と自己レビュー | 独立レビューインスタンスを使用 |
| CI/CDで対話モード実行 | -p(--print)フラグで非対話モード |
| アンチパターン | 正しいアプローチ |
|---|---|
| “be conservative”のような曖昧な指示 | 具体的カテゴリ基準とfew-shot例 |
tool_choice: "auto"でテキスト返却を許容 | tool_choice: "any"でツールコール保証 |
| 情報がソースにない場合のリトライ | リトライの限界を認識し別手段を検討 |
| ブロッキングワークフローにバッチAPI | リアルタイムAPI(バッチはレイテンシSLAなし) |
| アンチパターン | 正しいアプローチ |
|---|---|
| サイレントエラー抑制(空結果を成功として返す) | 構造化エラーコンテキストを返却 |
| 単一障害で全体停止 | 部分結果活用+代替手段で補完 |
| 全体精度97%で自動化承認 | 文書タイプ別・フィールド別の精度検証 |
| 矛盾する統計で一方を恣意的に選択 | 両方を出典付きで提示 |
| 感情分析スコアでエスカレーション判断 | 顧客の明示的要求と構造化基準 |
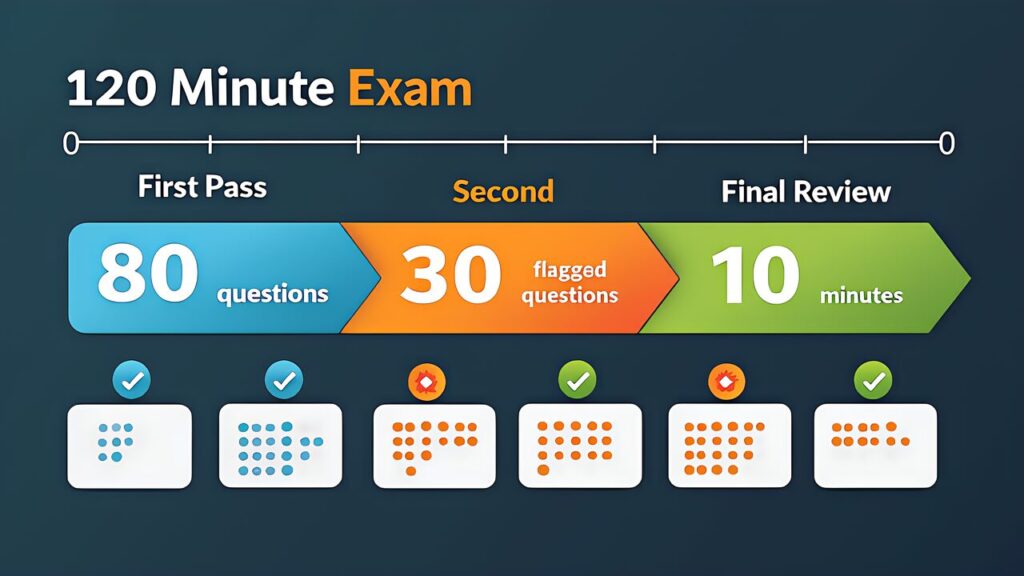
具体的には、120分÷60問 = 2分/問。具体的には、ただし、すべての問題が同じ難易度ではない。
| フェーズ | 時間 | アクション |
|---|---|---|
| 第1パス(0-80分) | 80分 | 全60問を通す。確信のある問題に解答し、迷う問題にフラグ |
| 第2パス(80-110分) | 30分 | フラグ付き問題を再検討。消去法で絞り込み |
| 最終確認(110-120分) | 10分 | 全体の見直し。未回答がないか確認 |
加えて、CCAの4択問題では、3つのディストラクターは「部分的に正しいが特定の観点で最適でない」選択肢だ。特に、以下のパターンで消去する。
例えば、D1(27%)+ D3(20%)= 47%。つまり、この2ドメインだけで全体の半分近くを占める。D1とD3に強い受験者は、D5で数問落としても合格圏内に入れる。逆に、D1に弱点がある場合は最優先で補強すべきだ。
結論として、カスタマーサポートエージェントのprocess_refundツールが、get_customerを完了せずに呼び出されるケースが12%発生している。例えば、最も効果的な対策はどれか。
したがって、A) システムプロンプトに「必ずget_customerを先に呼ぶこと」と追加する
B) few-shot例で正しい順序を示す
C) プログラマティックな前提条件ゲートでget_customer完了をブロックする
D) process_refundのツール記述に順序の注意書きを追加する
とりわけ、正解: C — 決定論的コンプライアンスが必要な場合、プロンプト指示(A, B, D)では非ゼロの失敗率が残る。しかし、コードレベルでの強制が唯一の保証手段だ。
一方、Web検索サブエージェントがタイムアウトした。したがって、コーディネータへの最も適切な報告方法はどれか。
一方、A) 空の結果リストを返す
B) 「検索サービス利用不可」というエラーメッセージを返す
C) ワークフロー全体を中止する
D) 構造化エラーコンテキスト(障害種別、試行クエリ、部分結果、代替手段、リトライ可否)を返す
まず、正解: D — Aはサイレントエラー抑制、Bは汎用エラーステータス、Cは単一障害全体停止。加えて、いずれもアンチパターンだ。
同様に、CI/CDパイプラインでClaude Codeを使ったコードレビューを自動化したい。同様に、夜間の定期レポート生成も行う。最も適切な構成はどれか。
最終的に、A) 両方ともリアルタイムAPIで実行する
B) 両方ともMessage Batches APIで実行する
C) コードレビューはリアルタイムAPI(-pフラグ)、夜間レポートはMessage Batches APIで実行する
D) コードレビューはMessage Batches API、夜間レポートはリアルタイムAPIで実行する
さらに、正解: C — コードレビューはプリマージチェックでブロッキングワークフローのため、レイテンシSLAのないバッチAPIは不適切。結論として、夜間レポートはレイテンシ非依存のため、50%コスト削減のバッチAPIが最適だ。
とりわけ、データ抽出システムの全体精度が97%で、本番導入を検討している。とりわけ、次のステップとして最も適切なのはどれか。
また、A) 97%は十分な精度なので、即座に全自動化を開始する
B) 文書タイプ別・フィールド別の精度を層化ランダムサンプリングで検証する
C) 信頼度スコアが95%以上の結果のみ自動化する
D) 人間レビューを完全に廃止し、コスト削減を優先する
正解: B — 全体精度は特定カテゴリの低パフォーマンスを隠す(例: 手書き請求書72%)。一方、信頼度スコア(C)は較正されていなければ意味がない。まず粒度の高い検証が必要だ。
結論として、マルチエージェント研究システムで「AI×クリエイティブ産業」を調査したが、結果が視覚芸術分野のみだった。まず、最も根本的な原因はどれか。
具体的には、A) Web検索サブエージェントの障害
B) コーディネータのタスク分解が狭すぎる
C) サブエージェントのツール記述が不十分
D) コンテキストウィンドウの不足
特に、正解: B — 音楽・映像・文学など他の分野がカバーされなかったのは、コーディネータが調査範囲を視覚芸術に限定してタスクを分解したため。最終的に、サブエージェントは与えられたタスクを正しく実行したが、タスク自体のスコープが不十分だった。
つまり、本シリーズの全7記事を以下にまとめる。
| # | 記事 | 主要ドメイン |
|---|---|---|
| Day 1 | CCA Foundations試験 完全ガイド 2026 | 全体概要 |
| 第2日 | D1前半: エージェントループとマルチエージェント設計 | D1(T1.1-1.3) |
| 第3日 | D1後半: ワークフロー、フック、タスク分解 | D1(T1.4-1.7) |
| 第4日 | D2: ツール設計とMCP統合 | D2 |
| 第5日 | D3: Claude Code設定とワークフロー | D3 |
| 第6日 | D4: プロンプトエンジニアリングと構造化出力 | D4 |
| 第7日 | 本記事(D5 + 総まとめ) | D5 + 全体 |
さらに、CCA Foundations試験は、Claude APIとエージェントシステムの「設計判断の質」を問う試験だ。さらに、暗記ではなく、「この状況で最適な設計判断は何か」を素早く判断する力が求められる。
本シリーズで解説したD1からD5の知識を横断的に理解し、アンチパターンを確実に識別できるようになれば、合格点720/1000は十分に到達可能だ。特に以下の3つの判断原則を心に刻んでほしい。
また、CCA試験 コンテキスト管理 信頼性 まとめとして本記事が、受験者の最終確認に役立つことを願う。試験の成功を祈る。
さらに詳しい情報はAnthropic公式サイトでご覧いただけます。
さらに深く学ぶために: 本記事はCCA試験の設計判断パターンを概説したものです。また、合格に向けた実践的な準備には、Anthropic Academy公式コースでのハンズオン学習と、模擬問題サイトでの演習を併せて実施してください。本シリーズの完全ガイド(Day 1)で推奨する「3本柱」の学習戦略も参照してください。






