CCA試験対策 D2完全解説 — ツール設計とMCP統合で18%を確実に取る 結論として、CCA(Claude Certified Architect)Foundations試験のDomain 2はCCA試験 ツール設計 MCP統合 に関する領域であり、全体の18%を占める。つまり、LLMがツールを正しく選択・実行するための設計原則、エラーハンドリング、MCPサーバー構成、組み込みツールの使い分けが出題される。 さらに、この記事では、試験ガイドのTask 2.1〜2.5を完全に網羅し、コード例・JSON Schema・模擬問題を交えながら合格に必要な知識を体系的に解説する。さらに、前回のDomain 1解説 で学んだエージェントループの知識を土台に、ツール層の設計へと進もう。ツールインターフェース設計 — descriptionが選択の生命線(T2.1) なぜdescriptionが最重要なのか 具体的には、LLMはツールのdescriptionフィールドを読んで、どのツールを呼び出すか判断する。特に、これがCCA試験 ツール設計 MCP統合の領域で最も重要な概念だ。つまり、コード内部のロジックではなく、説明文の質 がツール利用の正確性を左右する。 また、descriptionが不十分な場合、以下の問題が発生する。さらに、選択の不安定化 : 似た名前のツールが複数あると、LLMがランダムに近い選択をする また、誤ルーティング : get_customerとlookup_orderの区別がつかず、顧客情報の問い合わせで注文検索ツールが呼ばれる 具体的には、システムプロンプトの干渉 : システムプロンプト内のキーワードが意図せずツール選択に影響を与える 悪い定義と良い定義の比較 つまり、以下のコード例で、descriptionの質がどれほど重要かを確認しよう。 悪い定義 — 最小限の説明 さらに、tools = [{
"name": "get_customer",
"description": "Gets customer info",
"input_schema": {
"type": "object",
"properties": {
"id": {"type": "string"}
}
}
}]
良い定義 — 用途・フォーマット・境界を明示 重要なポイント tools = [{
"name": "get_customer",
"description": "Retrieves customer profile by customer ID "
"(format: CUST-XXXXX). Returns name, email, "
"account status, order history summary. "
"Use this when you need customer details "
"for support cases. "
"Do NOT use for order lookups "
"- use lookup_order instead.",
"input_schema": {
"type": "object",
"properties": {
"customer_id": {
"type": "string",
"description": "Customer ID in format "
"CUST-XXXXX (e.g., CUST-12345)"
}
},
"required": ["customer_id"]
}
}]
要素 説明 入力フォーマット customer_idの形式を明示(例: CUST-XXXXX)クエリ例 「サポートケースで顧客情報が必要な場合に使用」 エッジケース 「注文の検索には使用しないこと」 境界の明示 他ツールとの役割分担をdescription内に記述
汎用ツールの分割 例えば、1つの汎用ツール(例: search_database)を目的別に分割すると、LLMの選択精度が向上する。 また、search_database → lookup_customer_by_email + lookup_order_by_id + search_products_by_keyword つまり、各ツールの責務が明確になり、LLMの判断負荷が下がる。模擬問題 具体的には、Q : get_customerとlookup_orderを両方持つシステムで、顧客からの問い合わせが誤ったツールにルーティングされる。また、最も効果的な対処は? 特に、A) few-shotプロンプトでルーティング例を追加する
B) 各ツールのdescriptionを拡充し、用途・入力形式・他ツールとの境界を明記する
C) ツール名をより具体的に変更する
D) ルーティング専用の分類レイヤーを追加する したがって、正解はB — descriptionの改善が根本原因への対処。したがって、ツール名変更やルーティング層の追加は間接的な対処であり、試験では不正解になりやすい。 構造化エラーレスポンス — isErrorだけでは足りない(T2.2) isErrorフラグとエラーメタデータ さらに、MCPではツール結果にisErrorフラグを設定でき、LLMにエラー発生を明示的に伝達する。しかし、ただしフラグだけでは不十分で、構造化されたエラーメタデータ がリカバリ判断の鍵となる。 しかし、汎用メッセージ("Operation failed")だけでは、LLMは以下の判断ができない。特に、リトライすべきか? → 判断不能 つまり、入力を修正すべきか? → どのパラメータか不明 例えば、ユーザーに何を伝えるべきか? → 有用な情報がない エラーカテゴリの4分類 特に、特に、CCA試験では、以下の4カテゴリの区別が頻出する。カテゴリ 例 リトライ可否 対処 transient タイムアウト、一時的なネットワーク障害 可 再試行 validation 不正な入力形式、必須パラメータ欠落 不可(修正後は可) 入力を修正して再送 business ポリシー違反(返金上限超過など) 不可 エスカレーション permission 権限不足、認証切れ 不可(通常) 権限確認・再認証
構造化エラーレスポンスの実装例 例えば、ビジネスルール違反(リトライ不可) つまり、{
"type": "tool_result",
"tool_use_id": "toolu_abc123",
"is_error": True,
"content": json.dumps({
"errorCategory": "business",
"isRetryable": False,
"message": "Refund amount $750 exceeds "
"policy limit of $500",
"suggestedAction": "escalate_to_supervisor",
"context": {
"requested_amount": 750,
"policy_limit": 500
}
})
}
一時的エラー(リトライ可能) 重要なポイント {
"type": "tool_result",
"tool_use_id": "toolu_def456",
"is_error": True,
"content": json.dumps({
"errorCategory": "transient",
"isRetryable": True,
"message": "Database connection timed out "
"after 30s",
"suggestedAction": "retry_with_backoff",
"retryAfterMs": 5000
})
}
サブエージェントのエラー伝播ルール 具体的には、マルチエージェント構成での原則は3つ。しかし、サブエージェントはローカルでリカバリを試みる (リトライ、入力修正など) したがって、解決不能なエラーのみ コーディネーターに伝播する 加えて、伝播する際は、試行した対処と結果も含める 模擬問題 例えば、Q : ビジネスルール違反(返金上限超過)のエラーレスポンスに含めるべき要素の組み合わせとして最も適切なものは? しかし、A) エラーメッセージのみ
B) isRetryable: false、ポリシー上限と要求額のコンテキスト、推奨アクション(エスカレーション)
C) isRetryable: trueとリトライ間隔
D) 汎用エラーステータスとHTTPステータスコード つまり、正解はB — ビジネスルール違反はリトライ不可。加えて、コンテキスト(上限額・要求額)と推奨アクションを含めることで、LLMが適切な次のステップを判断できる。 ツール数と選択信頼性の関係 特に、ツール数が増えると選択の信頼性が低下する。例えば、18個のツールを持つエージェントより、4〜5個に絞ったエージェント の方が正確にツールを選択できる。結論として、これはCCA試験 ツール設計 MCP統合の中核的な設計原則だ。モード 値 動作 使用場面 auto "auto"モデルがツール使用かテキスト応答かを判断 汎用的な会話エージェント any "any"必ずいずれかのツールを呼び出す(どれかはモデルが選択) ツール呼び出しを保証したいワークフロー forced {"type": "tool", "name": "specific_tool"}特定のツールを強制的に呼び出す パイプラインの固定ステップ
コード例 したがって、# auto: モデルが判断(デフォルト)
response = client.messages.create(
model="claude-sonnet-4-6",
tools=tools,
tool_choice={"type": "auto"},
messages=messages
)
# any: 必ずツールを呼ぶが、
# どれかはモデルが選ぶ
response = client.messages.create(
model="claude-sonnet-4-6",
tools=tools,
tool_choice={"type": "any"},
messages=messages
)
# forced: 特定ツールを強制
response = client.messages.create(
model="claude-sonnet-4-6",
tools=tools,
tool_choice={
"type": "tool",
"name": "lookup_order"
},
messages=messages
)
重要なポイント スコープ付きツールアクセス エージェントには役割に必要なツールのみ を付与する。同様に、顧客対応エージェント: get_customer, lookup_order, create_ticket さらに、在庫管理エージェント: check_inventory, update_stock, reorder_item また、横断的に必要なツールは限定的に追加(例: verify_factを合成エージェントに付与) fetch_urlのような汎用ツールは、目的に応じた制約付きツールに置換する。 加えて、fetch_url → load_document(url, allowed_domains=["docs.example.com"])模擬問題 Q : 合成エージェントがファクトチェックのためにコーディネーターを経由している。したがって、レイテンシを改善するには? 同様に、A) 合成エージェントにスコープ付きのverify_factツールを直接付与し、コーディネーターへの往復を排除する
B) コーディネーターのレスポンスキャッシュを追加する
C) ファクトチェックのステップを削除する
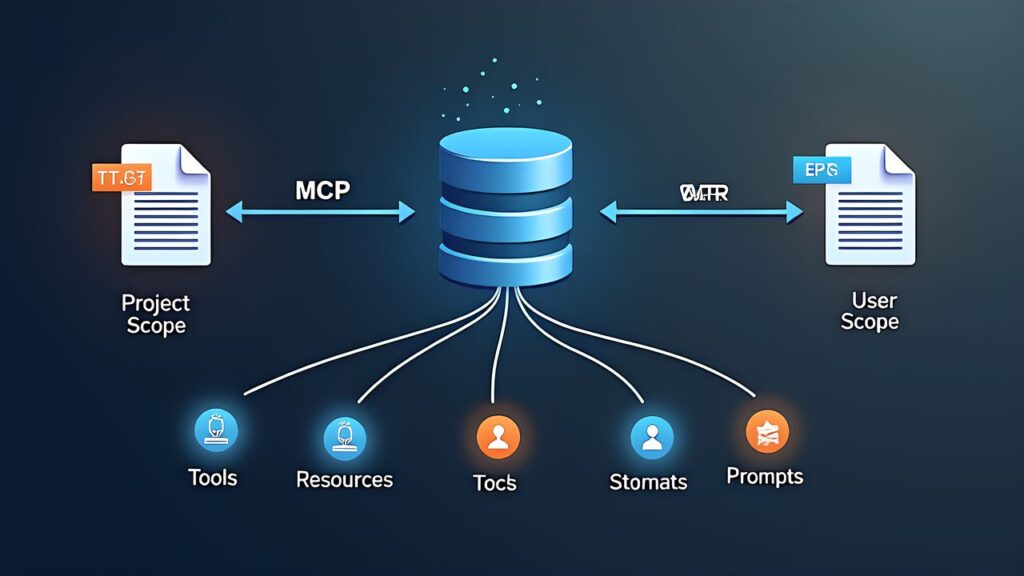
D) コーディネーターにより高速なモデルを使用する 結論として、正解: A — スコープ付きツールを直接付与することで、コーディネーターへの不要な往復を排除し、レイテンシを改善する。MCPサーバーの統合 — 構成とスコープを理解する(T2.4) MCPの構成と接続 このプロトコルのサーバーは.mcp.json(プロジェクトスコープ)または~/.claude.json(ユーザースコープ)で構成する。つまり、接続時にツールが自動検出され、複数のMCPサーバーのツールが同時に利用可能になる。スコープの使い分け スコープ ファイル 用途 プロジェクト .mcp.json(リポジトリルート)チーム共有のMCPサーバー設定 ユーザー ~/.claude.json個人環境のMCPサーバー設定
.mcp.jsonはリポジトリにコミットされるため、チーム全員が同じMCPサーバー設定を使える。具体的には、~/.claude.jsonは個人のマシンに閉じた設定で、個人用のAPIトークンやローカル環境に依存するサーバーに適している。構成例 {
"mcpServers": {
"github": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-github"
],
"env": {
"GITHUB_TOKEN": "${GITHUB_TOKEN}"
}
},
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/path/to/dir"
],
"env": {}
}
}
}
環境変数の展開 : ${GITHUB_TOKEN}のように記述すると、実行時に環境変数の値が展開される。つまり、トークンをハードコードせずセキュアに管理できる。重要なポイント MCPの3つの機能 具体的には、CCA試験では、Tools・Resources・Promptsの3機能の区別が問われる。機能 説明 効果 Tools サーバーが提供する実行可能な操作 LLMが外部システムと対話 Resources コンテンツカタログ(Issueリスト、ドキュメント階層、DBスキーマ) 探索的なツール呼び出しを削減 Prompts 再利用可能なプロンプトテンプレート 一貫性のある操作パターンを提供
Resourcesの活用 加えて、Resourcesはサーバーが公開するコンテンツカタログであり、LLMが「何が利用可能か」を事前に把握できる。具体的には、GitHubサーバーのResources: リポジトリ一覧、Issue一覧、PR一覧 特に、DBサーバーのResources: テーブルスキーマ、利用可能なクエリ 効果: 「まずリスト取得→詳細取得」の探索的呼び出しが不要になる 模擬問題 一方、Q : .mcp.jsonと~/.claude.jsonの違いとして正しいものは? まず、A) .mcp.jsonはユーザー固有、~/.claude.jsonはプロジェクト固有
B) .mcp.jsonはプロジェクトスコープ(リポジトリ内で共有)、~/.claude.jsonはユーザースコープ(個人環境)
C) どちらも同一スコープで互換性がある
D) .mcp.jsonはCLI専用、~/.claude.jsonはAPI専用 最終的に、正解: B — .mcp.jsonはリポジトリルートに配置しチーム共有。特に、~/.claude.jsonは個人環境の設定。 組み込みツールの効果的使用 — 正しいツールを正しい場面で(T2.5) 各ツールの役割と使い分け 例えば、Claude Codeなどの環境に組み込まれたツールには、それぞれ明確な用途がある。ツール 用途 使用例 Grep コンテンツ検索(ファイル内容から検索) 関数名、エラーメッセージ、import文の検索 Glob ファイルパスのパターンマッチ 名前・拡張子でファイルを探す(**/*.test.ts) Read ファイル全体の読み取り ファイル内容の確認、設定ファイルの読み込み Write ファイル全体の書き込み 新規ファイル作成、全面的な書き換え Edit ユニークなテキストマッチによる部分編集 特定の関数やセクションの修正
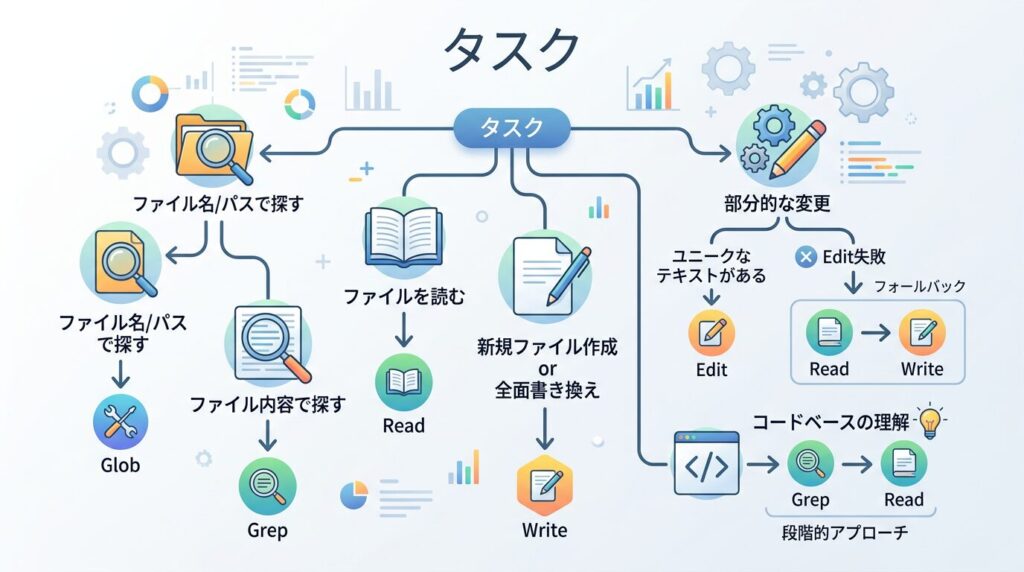
Grep vs Globの使い分け さらに、この判断は試験で頻出する。判断基準は単純だ。つまり、ファイルの中身 (コード、テキスト)を探す → Grep 例えば、例: getUserByIdを含むファイルを探す しかし、ファイル名やパス を探す → Glob したがって、例: *.config.tsというファイルを探す Editの失敗と対処 また、Editツールはファイル内でユニークなテキストをマッチさせて部分置換する。つまり、マッチが曖昧(複数箇所に一致)だと失敗する。加えて、失敗時のフォールバック : Readでファイル全体を取得 → 内容を修正 → Writeで書き戻す 同様に、Editが使えるならEditを優先(差分のみ送信するため効率的) 段階的な理解の構築 したがって、全ファイルを一括で読み込むのではなく、段階的にコードベースを理解する。さらに、Grep でimport/require文を検索 → 依存関係を把握 また、Glob で関連ファイルの一覧を取得 → 構造を把握 具体的には、Read で必要なファイルのみ読み込み → 詳細を確認 判断ツリー 具体的には、タスク
├── ファイル名/パスで探す → Glob
├── ファイル内容で探す → Grep
├── ファイルを読む → Read
├── 新規ファイル作成 or 全面書き換え → Write
├── 部分的な変更
│ ├── ユニークなテキストがある → Edit
│ └── Edit失敗 → Read + Write(フォールバック)
└── コードベースの理解
└── Grep → Read の段階的アプローチ
模擬問題 Q : 特定のエラーメッセージがコードベースのどこで発生しているか調べたい。例えば、どのツールを使うべきか? 特に、A) Glob
B) Grep
C) Read
D) Edit つまり、正解: B — ファイル内容からテキストを検索するツールはGrep。しかし、Globはファイル名のパターンマッチに使う。 例えば、Q : Editツールが失敗した場合のフォールバックとして最も適切なのは? しかし、A) Bashでsedコマンドを実行する
B) Writeで空ファイルを作成し直す
C) Readでファイルを読み取り、内容を修正してWriteで書き戻す
D) Grepで該当箇所を検索してからEditを再試行する したがって、正解: C — Editのフォールバックは「Read → 修正 → Write」のパターン。実践演習:MCPサーバーを設計する シナリオ設定 とりわけ、社内のConfluenceライクなドキュメント管理システムに接続するMCPサーバーを設計する。加えて、要件は以下の3つだ。特に、ドキュメントの検索・閲覧ができること つまり、ドキュメントの作成・編集ができること 例えば、ドキュメントの権限管理情報を参照できること ステップ1:ツール設計(T2.1の適用) まず、1つの汎用ツールmanage_documentではなく、目的別に分割する。ツール名 description(要点) 分割の理由 search_docsキーワード/タグでドキュメントを検索。タイトル・要約・最終更新日を返す。特定ドキュメントの内容取得にはread_docを使用 検索と閲覧の分離 read_docドキュメントID(形式: DOC-XXXXX)で全文を取得。Markdown形式で返す 単一ドキュメントの読み取りに特化 create_doc新規ドキュメントを作成。title, content, tags, spaceが必須 作成と編集の分離 update_doc既存ドキュメントのcontentを更新。doc_idとcontentが必須。タイトル変更にはrename_docを使用 部分更新に限定 check_permissionsドキュメントまたはスペースの閲覧・編集権限を確認。変更はできない 読み取り専用
search_docsに「特定ドキュメントの内容取得にはread_docを使用」と書くことで、LLMが検索結果から直接内容を取得しようとする誤ルーティングを防ぐ。ステップ2:エラーレスポンス設計(T2.2の適用) 加えて、各ツールのエラーレスポンスに4カテゴリの分類を適用する。# 権限エラー(permission)— リトライ不可
{
"is_error": True,
"content": {
"errorCategory": "permission",
"isRetryable": False,
"message": "DOC-12345 の編集権限がありません",
"suggestedAction": "request_access",
"context": {
"doc_id": "DOC-12345",
"required_role": "editor",
"current_role": "viewer"
}
}
}
# 一時的エラー(transient)— リトライ可能
{
"is_error": True,
"content": {
"errorCategory": "transient",
"isRetryable": True,
"message": "ドキュメントサーバーが応答しません",
"suggestedAction": "retry_with_backoff",
"retryAfterMs": 3000
}
}
isRetryable: Falseとし、suggestedActionに"verify_doc_id"を指定する。さらに、LLMはこの情報から「ドキュメントIDを再確認して別のIDで検索する」という判断ができる。重要なポイント ステップ3:MCP構成とスコープ設計(T2.4の適用) また、プロジェクトスコープとユーザースコープの使い分けを設計する。同様に、// .mcp.json(プロジェクトスコープ — チーム共有)
{
"mcpServers": {
"docs": {
"command": "npx",
"args": ["-y", "@company/mcp-docs-server"],
"env": {
"DOCS_API_URL": "${DOCS_API_URL}",
"DOCS_API_TOKEN": "${DOCS_API_TOKEN}"
}
}
}
}
${DOCS_API_TOKEN}で環境変数から展開する。また、ハードコードはセキュリティリスクだ。個人の認証情報が必要な場合は~/.claude.jsonに分離する。ステップ4:ツール配分の最適化(T2.3の適用) つまり、MCPサーバーのツールを全エージェントに付与するのではなく、役割に応じて配分する。エージェントの役割 付与するツール 付与しない理由 リサーチ担当 search_docs, read_doc編集権限は不要 コンテンツ作成担当 search_docs, read_doc, create_doc, update_doc権限管理は管理者が担当 管理者 全ツール フルアクセスが必要
update_docを付与しないことで、調査中の誤編集を構造的に防止する。具体的には、これはDomain 1のT1.3で学んだ最小権限の原則と同じ考え方だ。ステップ5:Resourcesの活用(T2.4の適用) 特に、MCPサーバーにResourcesを実装し、探索的なツール呼び出しを削減する。Resource 内容 削減効果 スペース一覧 利用可能なドキュメントスペースとその説明 「まずスペースを検索して」という手順が不要に 最近の更新 直近24時間に更新されたドキュメント一覧 日次レビュー時のツール呼び出し削減 テンプレート一覧 利用可能なドキュメントテンプレート テンプレート検索のツール呼び出し削減
設計チェックポイント チェック項目 該当タスク 各ツールのdescriptionに用途・フォーマット・境界が含まれるか T2.1 エラーレスポンスにerrorCategoryとisRetryableが含まれるか T2.2 エージェントごとにツールが最小限に配分されているか T2.3 環境変数でトークンを管理しているか T2.4 Resourcesで探索的呼び出しを削減しているか T2.4
Domain 2 総合チェックリストと出題パターン 5つの出題パターン 具体的には、CCA試験 ツール設計 MCP統合の領域では、以下5つのパターンが頻出する。 とりわけ、パターン1: ツール誤選択の修正 「エージェントが間違ったツールを呼び出す」→ descriptionの改善が正解。特に、コード側のロジック変更やツール名変更は不正解。 一方、パターン2: エラーハンドリングの設計 「エージェントがエラー後にリトライすべきか判断できない」→ 構造化エラーレスポンスにisRetryableとerrorCategoryを含めるのが正解。 まず、パターン3: ツール数の最適化 「18個のツールを持つエージェントの選択精度が低い」→ 役割ごとにエージェントを分割し、各エージェントのツール数を4〜5個に絞るのが正解。 最終的に、パターン4: MCP構成の理解 環境変数、スコープ(プロジェクト vs ユーザー)、Resourcesの役割を問う問題。 さらに、パターン5: 組み込みツールの選択 「Xを達成したい。つまり、どのツールを使うべきか?」→ Grep / Glob / Read / Write / Editの判断ツリーに基づいて回答。合格のための最終チェックリスト しかし、ツールdescriptionが選択の最重要メカニズムであることを説明できるか したがって、良いdescriptionの4要素(フォーマット、用途、境界、例)を列挙できるか 加えて、MCPのisErrorフラグと構造化エラーメタデータの設計を説明できるか 同様に、エラーカテゴリ(transient / validation / business / permission)を区別できるか さらに、isRetryableの判断基準を説明できるか また、サブエージェントのエラー伝播ルール(ローカルリカバリ優先)を理解しているか 具体的には、tool_choiceの3モード(auto / any / forced)の違いと使用場面を説明できるか 特に、ツール数と選択信頼性の関係(少ない方が正確)を理解しているか つまり、スコープ付きツールアクセスの原則を説明できるか 例えば、.mcp.jsonと~/.claude.jsonのスコープの違いを説明できるか しかし、環境変数展開${VAR}の仕組みを理解しているか したがって、MCPの3機能(Tools / Resources / Prompts)を区別できるか 加えて、Grep / Glob / Read / Write / Editの使い分けを即答できるか 同様に、Edit失敗時のフォールバック戦略を説明できるか まとめ — 18%を落とさないための戦略 加えて、Domain 2は5つのTaskで構成され、全体の18%を占める。出題傾向は明確だ。 また、ツール設計 : descriptionの質がすべて。例えば、LLMはコードを見ない。説明文を見る。 具体的には、エラーハンドリング : isRetryableとerrorCategoryで構造化する。しかし、汎用メッセージは不正解の選択肢として登場する。 特に、ツール配分 : 少ない方が正確。したがって、スコープ付きアクセスでレイテンシを削減。 つまり、MCP構成 : .mcp.json(プロジェクト)vs ~/.claude.json(ユーザー)。加えて、Resourcesが探索的呼び出しを削減。 例えば、組み込みツール : Grep(中身)とGlob(ファイル名)の違い。同様に、EditのフォールバックはRead + Write。重要なポイント しかし、次回のDomain 3解説 では、CLAUDE.mdの階層構造、カスタムスラッシュコマンド、CI/CD統合といった実務直結の設定・ワークフロー領域に進む。さらに、Domain 2で学んだツール設計の知識が、Domain 3のClaude Code構成で具体的にどう活きるかを確認しよう。さらに深く学ぶために : 本記事はCCA試験の設計判断パターンを概説したものです。また、合格に向けた実践的な準備には、Anthropic Academy公式コース でのハンズオン学習と、模擬問題サイト での演習を併せて実施してください。本シリーズの完全ガイド(Day 1) で推奨する「3本柱」の学習戦略も参照してください。さらに詳しい情報はModel Context Protocol公式サイト でご覧いただけます。
ABOUT ME
AIを使って、毎日の生活をもっと快適にするアイデアや将来像を発信しています。
初心者にもわかりやすく、すぐに取り入れられる実践的な情報をお届けします。 Sharing ideas and visions for a better daily life with AI.
Practical tips that anyone can start using right away.