CCA試験対策 D2完全解説 — ツール設計とMCP統合で18%を確実に取る
ゲンキ swiftwand.ai
特に、CCA Foundations試験で最大配点(27%)を占めるDomain 1「Agentic Architecture & Orchestration」。つまり、このドメインを落とせば合格はない。一方、ここを制すれば全体の約3割を確保できる。
具体的には、本記事はCCA試験対策シリーズ第2回として、Domain 1の前半3タスク(T1.1〜T1.3)を徹底解説する。さらに、CCA試験のエージェントループとマルチエージェントの設計パターンを、Pythonコード付きで理解し、試験本番で迷わない判断力を身につけよう。
シリーズ第1回のCCA Foundations試験 完全ガイド 2026を未読の方は、まず試験全体像を把握してから本記事に戻ることを推奨する。
加えて、CCA Foundationsの5ドメインの中で、Domain 1は27%という突出した配点を持つ。つまり、全60問中16〜17問がこのドメインから出題される計算だ。
例えば、合格点720/1000(72%)を達成するために、Domain 1で80%以上を取ることが最も効率的な戦略となる。具体的には、Domain 1の7タスク中、本記事ではTask 1.1〜1.3を扱う。さらに、残りのTask 1.4〜1.7はD1後編で解説する。
| タスク | テーマ | 本記事 |
|---|---|---|
| T1.1 | エージェントループの設計と実装 | 対象 |
| T1.2 | マルチエージェントorchestration | 対象 |
| T1.3 | サブエージェントのスポーンとコンテキスト受渡し | 対象 |
| T1.4 | 多段ワークフローとエンフォースメント | D1後編 |
| T1.5 | Agent SDKフック | D1後編 |
| T1.6 | タスク分解戦略 | D1後編 |
| T1.7 | セッション状態と再開 | D1後編 |

したがって、エージェントループ(Agentic Loop)とは、Claudeがツールを使いながら自律的にタスクを遂行する反復サイクルだ。しかし、単なる1回のAPI呼び出しではない。具体的には、以下のサイクルを繰り返す:
リクエスト送信 → レスポンス受信 → stop_reason検査 → ツール実行 → 結果を会話に追加 → 次のイテレーション
特に、このループの核心はstop_reasonフィールドにある。つまり、Claudeは自身の判断で「まだツールを使う必要がある」か「タスク完了」かを示す。したがって、開発者はこの構造的シグナルに基づいてループの継続・終了を制御する。
具体的には、Messages APIのレスポンスに含まれるstop_reasonの値と、それに対応するループ動作を整理する。
stop_reasonの値 | 意味 | ループの動作 |
|---|---|---|
"tool_use" | Claudeがツール呼び出しを要求 | ツールを実行し、結果を返して継続 |
"end_turn" | Claudeがタスク完了と判断 | 最終テキストを取得して終了 |
"max_tokens" | トークン上限に到達 | 切り詰められた応答の処理が必要 |
特に、重要なのは、stop_reasonはAPIが構造的に返すフィールドだという点だ。しかし、Claudeのテキスト出力を解析して判断するものではない。
一方、CCA試験 エージェントループの理解には、実際のコードが最も有効だ。具体的には、以下はMessages APIを使った基本的なエージェントループの実装である。
import anthropic
client = anthropic.Anthropic()
messages = [
{"role": "user", "content": "東京の今日の天気を調べて、傘が必要か教えて"}
]
tools = [
{
"name": "get_weather",
"description": "指定都市の現在の天気情報を取得する",
"input_schema": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "都市名"}
},
"required": ["city"]
}
}
]
# === エージェントループ ===
while True:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
tools=tools,
messages=messages
)
# ステップ1: stop_reasonを検査(ループの心臓部)
if response.stop_reason == "end_turn":
final_text = next(
(block.text for block in response.content
if hasattr(block, "text")),
""
)
print(final_text)
break
if response.stop_reason == "tool_use":
# ステップ2: tool_useブロックを探してツール実行
tool_results = []
for block in response.content:
if block.type == "tool_use":
result = execute_tool(block.name, block.input)
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": str(result)
})
# ステップ3: アシスタント応答+ツール結果を会話に追加
messages.append({"role": "assistant", "content": response.content})
messages.append({"role": "user", "content": tool_results})具体的には、注目すべきポイントは3つある。while Trueによる無限ループ、stop_reasonによる分岐制御、そしてtool_use_idによる対応付けだ。tool_resultのtool_use_idは、対応するtool_useブロックのidと必ず一致させる必要がある。
同様に、CCA試験では「何が正しいか」だけでなく「何が間違いか」も問われる。具体的には、以下の3つのアンチパターンは出題頻度が高い。
| アンチパターン | なぜ間違いか |
|---|---|
| Claudeのテキスト出力に「完了」等の文字列があるかパースしてループ終了を判定 | 自然言語は曖昧。stop_reasonという構造的シグナルが存在するのに無視している |
for i in range(5):のような任意のイテレーション上限を主要な停止メカニズムにする | タスクの完了と無関係。3回で終わるタスクも10回必要なタスクもある |
| アシスタントのテキストブロックが存在する=完了と判断 | Claudeはツール呼び出しと同時にテキストも返すことがある。テキスト有無は完了の指標にならない |
試験のコツ: 「ループをいつ止めるか」という問いには、常にstop_reason == "end_turn"が正解だ。
Q. エージェントループで、Claudeが
stop_reason: "tool_use"を返し、レスポンスのcontentにtextブロックとtool_useブロックの両方が含まれている。次に何をすべきか?
正解: ツールを実行し、tool_resultを会話に追加してループを継続する。つまり、テキストブロックが存在してもstop_reasonが"tool_use"であればタスクは未完了。例えば、テキストはClaudeの「考え中」の説明であることが多い。
とりわけ、CCA試験 マルチエージェントシステムの設計パターンとして、最も重要なのがHub-and-Spoke(ハブ&スポーク)モデルだ。
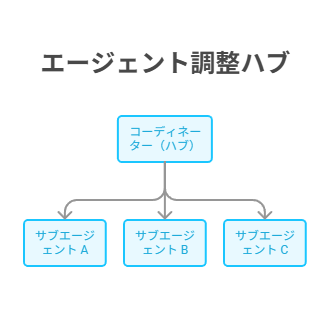
結論として、Coordinator(ハブ)がすべての通信を仲介する。つまり、サブエージェント同士は直接通信しない。特に、この原則はCCA試験で繰り返し問われる。
| 責務 | 説明 |
|---|---|
| タスク分解 | ユーザー要求を適切な粒度のサブタスクに分割 |
| 委任 | 各サブタスクを適切なサブエージェントに割り当て |
| 結果集約 | サブエージェントの出力を統合し、矛盾やギャップを検出 |
| 反復改善 | 集約結果にギャップがあれば再委任→再合成 |
| 動的選択 | クエリの要件に応じて、どのサブエージェントを使うか動的に判断 |
さらに、反復改善ループは見落とされがちだが重要だ。さらに、Coordinatorが合成出力のギャップを評価し、不足があれば追加のサブエージェントを起動して再合成する。しかし、一度の委任で完了とは限らない。
特に、サブエージェントはCoordinatorの会話履歴を自動的に継承しない。 とりわけ、これはCCA試験で最も頻出する概念の一つだ。
つまり、サブエージェントAの出力をサブエージェントBが必要とする場合、Coordinatorが仲介する。つまり、AからBへ直接渡すのはHub-and-Spoke原則に反する。
また、ユーザーが「AIがクリエイティブ産業に与える影響を調査して」と依頼した場合を考える。例えば、Coordinatorが「視覚芸術への影響」のみにサブタスクを分解すると、音楽、映画、文学、ゲームデザインなどの領域が漏れる。
つまり、タスク分解が狭すぎると、ユーザーの意図した網羅性を達成できない。さらに、Coordinatorは分解後にカバレッジを自己評価し、不足があれば追加のサブエージェントを起動すべきだ。
| パターン | 問題点 |
|---|---|
| サブエージェント間の直接通信 | Hub-and-spokeの原則に反する。Coordinatorが状態を追跡できなくなる |
| Coordinatorの全会話履歴をサブエージェントに共有 | コンテキストが肥大化し、サブエージェントの専門性が薄まる |
| 固定数のサブエージェントのみ使用 | クエリの要件に応じた動的な選択ができない |
Q. マルチエージェントシステムで、Coordinatorが統合結果を評価したところセキュリティ観点の分析が欠けていた。したがって、次のステップとして最も適切なものは?
正解: セキュリティ分析を担当する新たなサブエージェントを起動し(反復改善ループ)、その結果を既存の統合結果にマージする。

具体的には、サブエージェントの生成メカニズムはTaskツールである。CoordinatorのallowedToolsに"Task"が含まれている必要がある。
# AgentDefinitionの概念的構造
agent_definition = {
"description": "セキュリティ監査の専門エージェント",
"system_prompt": (
"あなたはセキュリティ専門家です。"
"提供されたコードの脆弱性を分析してください。"
),
"allowed_tools": ["read_file", "search_code"]
}
| 要素 | 役割 |
|---|---|
description | エージェントの目的をCoordinatorに説明する短い記述 |
system_prompt | サブエージェントの動作を定義するシステムプロンプト |
allowed_tools | サブエージェントが使用可能なツールの制限リスト |
allowed_toolsでサブエージェントの権限を最小限に絞ることで、意図しない操作を防止する。つまり、これは最小権限の原則(Principle of Least Privilege)の適用だ。
また、fork_sessionは、共有ベースラインから独立したブランチを作成する機能だ。
_├──-Fork-A-パフォーマンス最適化の検討_├──-Fork-B-セキュリティ強化の検討_└──-Fork-C-182121-1024x572.jpg)
セッション(共有ベースライン: コード分析完了)
├── Fork A: パフォーマンス最適化の検討
├── Fork B: セキュリティ強化の検討
└── Fork C: リファクタリングアプローチの検討
特に、各フォークは独立しており、互いの変更に影響されない。例えば、同じコードベースを異なる観点で並行分析したり、A/Bテスト的に異なるアプローチを試して比較する際に有効だ。
Coordinatorは1回のレスポンスで複数のTaskツールコールを発行できる。つまり、これにより並行実行が可能になる。
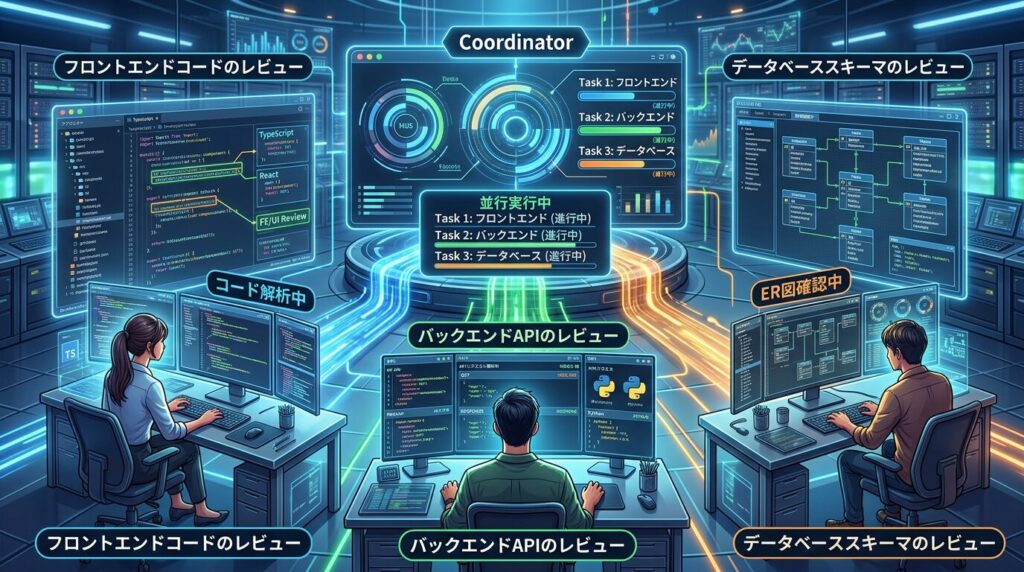
Coordinatorレスポンス:
├── Task call 1: "フロントエンドコードのレビュー"
├── Task call 2: "バックエンドAPIのレビュー"
└── Task call 3: "データベーススキーマのレビュー"
→ 3つのサブエージェントが並行実行
具体的には、順次実行と比較して、独立したタスクを並行に振ることでレイテンシを大幅に削減できる。
加えて、CCA試験 エージェントループの延長線上にある重要トピックとして、コンテキスト受渡しの設計がある。
| 方法 | 説明 |
|---|---|
| 明示的プロンプト含有 | 必要な情報をサブエージェントのプロンプトに直接記述する |
| 構造化データ形式 | コンテンツとメタデータを分離する(ソースURL、ページ番号等) |
| 目標指向プロンプト | 手順を指示するのではなく、研究目標と品質基準を指定する |
以下に良い例と悪い例を示す。
# 良い例: 目標指向 + 構造化コンテキスト
task_prompt = """
## 目標
以下のコードのセキュリティ脆弱性を特定し、
重要度順にランク付けしてください。
## 対象コード
ファイル: auth/middleware.py
関数: validate_token (行 45-89)
## 品質基準
- OWASP Top 10 に基づく分類
- 各脆弱性に修正提案を含める
"""
# 悪い例: 手順指示(サブエージェントの自律性を制限)
task_prompt = """
ステップ1: ファイルを読む
ステップ2: 脆弱性を探す
ステップ3: レポートを書く
"""
例えば、目標指向のプロンプトは、サブエージェントが自身の専門性を活かして最適なアプローチを選択する余地を残す。しかし、手順指示は一見親切だが、エージェントの自律性と柔軟性を損なう。
Q. サブエージェントにCoordinatorの全コンテキストを渡さない理由として、最も適切なものは?
(1) コンテキストウィンドウの無駄遣い (正解)
したがって、(2) 無関係な情報がサブエージェントの専門タスクを妨害する
一方、(3) 必要な情報だけを明示的に渡す方がタスクの精度が上がる。
同様に、ここまでの3タスクを統合した実践的なシナリオを考えてみよう。特に、これはCCA試験のシナリオベース出題に近い形式だ。
とりわけ、14ファイルのPull Requestをレビューするマルチエージェントシステムを設計する場合。
設計ポイント:
stop_reason == "end_turn"まで回る(T1.1: ループ制御)結論として、このようにT1.1〜1.3は独立した概念ではなく、実際のシステム設計では密接に連携する。
結論として、Domain 1の出題パターンには明確な傾向がある。
| 問いのパターン | 正解の傾向 | 不正解の傾向 |
|---|---|---|
| 「ループをいつ止めるか」 | stop_reasonによる判定 | 自然言語パース、イテレーション上限 |
| 「サブエージェントへの情報伝達」 | 明示的プロンプト含有 | 全コンテキスト共有、直接通信 |
| 「レビュー範囲の不足」 | 反復改善で追加エージェント起動 | 既存エージェントの再実行 |
| 「エージェントの権限」 | allowed_toolsで最小限に制限 | 全ツールへのアクセス付与 |
stop_reason、tool_use_id等のAPI構造を常に優先するさらに、ここまでの知識を実際の設計課題に適用してみよう。特に、この演習は、CCA試験のシナリオベース問題に対応する力を養うことを目的としている。
また、ECサイトのカスタマーサポートシステムを構築する。例えば、顧客からの問い合わせに対し、注文確認、返金処理、技術的トラブルシュート、FAQ回答の4つの機能を提供する。
まずHub-and-Spokeモデルに基づき、Coordinatorの責務を定義する。
coordinator_definition = {
"system_prompt": (
"あなたはカスタマーサポートのCoordinatorです。"
"顧客の問い合わせ内容を分析し、"
"適切なサブエージェントに委任してください。"
"全サブエージェントの結果を統合し、"
"顧客への最終回答を生成してください。"
),
"allowed_tools": ["Task", "respond_to_customer"]
}
つまり、Coordinatorは顧客と直接やり取りする唯一のエージェントだ。つまり、サブエージェントは裏側で専門タスクを処理し、結果をCoordinatorに返す。
特に、4つの専門サブエージェントを設計する。さらに、各エージェントには最小権限の原則を適用する。
| サブエージェント | allowed_tools | 禁止する理由 |
|---|---|---|
| 注文確認 | lookup_order, get_customer | 変更権限は不要 |
| 返金処理 | get_customer, process_refund, check_policy | ファイル操作は不要 |
| 技術サポート | search_knowledge_base, check_system_status | 顧客データへのアクセスは不要 |
| FAQ回答 | search_faq | 最小限のツールで十分 |
特に、返金処理エージェントにdelete_customerツールを付与しないのは意図的だ。不要な権限は事故の原因になる。
各サブエージェント内部では、stop_reasonに基づくエージェントループが動作する。以下は注文確認サブエージェントのループ設計だ。
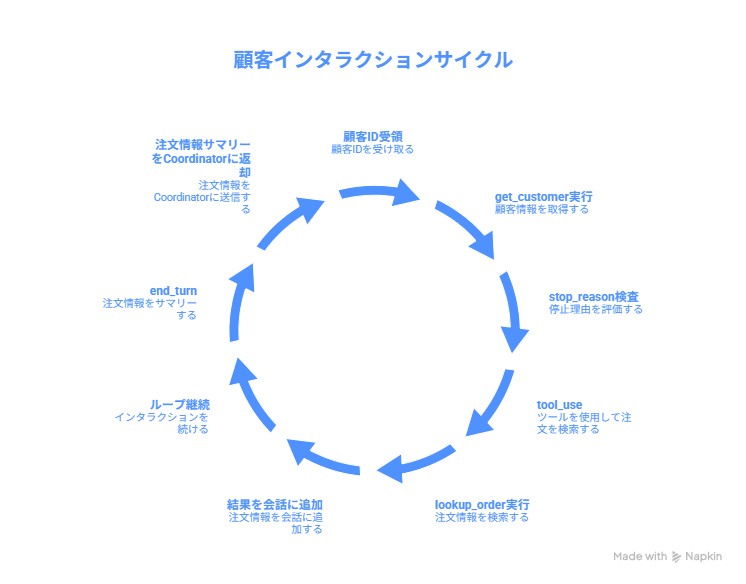
具体的には、ここで「注文情報が取得できたらループを止める」というテキストベースの判定は行わない。stop_reason == "end_turn"が唯一の正当な終了条件だ。
加えて、Coordinatorから返金処理サブエージェントへのコンテキスト受渡しを設計する。
# 目標指向プロンプト(良い例)
refund_task_prompt = """
## 目標
顧客C-98765の注文ORD-54321に対する返金を処理する。
## コンテキスト
- 顧客名: 田中太郎
- 注文金額: ¥12,800
- 返金理由: 商品不良(到着時に破損)
- 注文日: 2026-03-15
## 品質基準
- 返金ポリシーに準拠しているか確認する
- 返金額と理由をログに記録する
- ポリシー上限を超える場合はエスカレーションする
"""
例えば、Coordinatorの全会話履歴を渡すのではなく、返金処理に必要な情報だけを構造化して渡す。顧客との会話の文脈やFAQの検索結果など、返金処理に無関係な情報はサブエージェントのコンテキストを汚染するだけだ。
最終的に、この演習で確認すべき設計原則を整理する。
| チェック項目 | T1.1〜1.3のどの概念か |
|---|---|
| サブエージェント同士は直接通信しないか | T1.2: Hub-and-Spoke原則 |
各サブエージェントのループはstop_reasonで制御されているか | T1.1: 構造的シグナル |
| コンテキストは明示的に渡しているか(自動継承前提でないか) | T1.2: 分離コンテキスト |
allowed_toolsは最小限に絞られているか | T1.3: 最小権限の原則 |
| プロンプトは手順指示ではなく目標指向か | T1.3: コンテキスト設計 |
| Coordinatorは結果統合後にギャップを評価しているか | T1.2: 反復改善 |
したがって、CCA試験では、上記のような設計判断を問うシナリオ問題が出題される。各判断の「なぜ」を説明できる状態を目指そう。
一方、Domain 1前半の3タスクは、CCA Foundationsの得点源として最も重要な領域だ。
T1.1 エージェントループ: stop_reasonが唯一の正当な終了判定基準。自然言語パース、任意のイテレーション上限、テキストブロックの有無は全てアンチパターン。
T1.2 マルチエージェントorchestration: Hub-and-Spokeモデルで、Coordinatorが全通信を仲介。サブエージェントのコンテキストは分離され、必要な情報は明示的に渡す。
T1.3 サブエージェントスポーン: TaskツールとAgentDefinitionで定義。fork_sessionで分岐探索、並行Taskコールでレイテンシ削減。目標指向プロンプトが手順指示より優れる。
続編のD1後編では、Task 1.4〜1.7(エンフォースメント、SDKフック、タスク分解戦略、セッション管理)を解説する。
同様に、CCA試験 エージェントループ マルチエージェントの設計パターンは、単なる試験対策ではない。Claude APIを使った実用的なエージェントシステム構築の基盤知識だ。この知識を実装に落とし込むことで、試験対策と実務スキルを同時に向上させることができる。
とりわけ、D1前編の学習完了後は、以下の自己チェックで理解度を確認してほしい。
stop_reasonの3つの値(tool_use、end_turn、max_tokens)の処理方法を、コードなしで説明できるかfork_sessionと通常のTaskスポーンの違いを、ユースケース付きで説明できるか結論として、すべて「はい」なら、D1前編の理解は十分だ。「いいえ」の項目があれば、該当セクションを再読してから次に進むことを推奨する。
さらに詳しい情報はAnthropic公式ドキュメントでご覧いただけます。
さらに深く学ぶために: 本記事はCCA試験の設計判断パターンを概説したものです。合格に向けた実践的な準備には、Anthropic Academy公式コースでのハンズオン学習と、模擬問題サイトでの演習を併せて実施してください。本シリーズの完全ガイド(Day 1)で推奨する「3本柱」の学習戦略も参照してください。